
Birmingham library is real hi-tech – free access to microfilm scanners where you can also log on to your Drive / Dropbox / Cloud*.* storage to send the scans. Sweet … except the flaming scanned images get embedded in damn PDF files. How do we get those images back out ?
OK, you could use an online PDF extractor such as http://www.extractpdf.com/ which works just fine but when faced with several hundred scans this turns into an epic task.There’s always the “pay for” or “Free” apps (free, as in with free adware, virus, stoooopid unwanted browser plugins and lord knows what other crap) but hey, we’re programmers, we can do this.
Naturally, as a programmer I want to open a PDF as a byte stream and decode it all from the ground up. But I want those images and I want them NOW, so time to find a library. There are several libraries about, but the iTextSharp library sees appropriate since, if I read it right, I can use it provided I make no money from it and I supply the source code. Tick and tick.
One issue with the library is lack of real on-line documentation; there is http://www.afterlogic.com/ but a lot of detail is missing and examples are thin on the ground. I guess you need to buy one of the books (even free if you are feeling tight) and if I were developing a real application you can be darn sure I’d get one of these books. But I’m just hacking up a quick Mikey-mouse app, so here we go.
Start by downloading the latest library from iTextSharp. This is a zip file containing 7 zip files (and a notice.txt). We’ll only be using a tiny fraction of this library and all’s we need is the iTextSharp.dll contained in the itextsharp-dll-core.zip zip file. Add a reference to the dll in your project and lets make a start.
First, we need to open the pdf file. Guess we need the PdfReader class for that which is derived from IDisposable, so we can start with:
using( var pdfReader = new PdfReader(pdfFileName) { ... do some stuff }
Looking at intelisense, there is a function called PdfReader.ProcessContent(), one of whose parameters is a page number. So I feel a for-next loop or something coming on, but how many pages ? PdfReader has a page count property, its “NumberOfPages()”. Jollygood. PdfReader, however, is a low-level reader, think of it as a StreamReader. What we need is a parser of some kind. Ooh look, there’s a PdfReaderContentParser whose constructor accepts a PdfReader instance. now we are cooking and it only has one function of any consequence – ProcessContent().
ProcessContent() requires two parameters – the page number (easy) and an IRenderListener. The latter is basically a collection of four callback functions which will be called as the content is parsed and best of all we can ignore three of ‘em as they are to do with text !

IRenderListener
So, we just need to create a class on which to implement IRenderListener and pass an instance of that class to ProcessContent. Lets call this new class PdfImageCollection. So, our original loop becomes:
var imageCollection = new PdfImageCollection(); using (var pdfReader = new PdfReader(pdfFileName)) { var pdfParser = new PdfReaderContentParser(pdfReader); for(var iPage = 1; iPage <= pdfReader.NumberOfPages; iPage++) { pdfParser.ProcessContent(iPage, imageCollection); } }
So, on to our PdfImageCollection class, which will implement IRendererListener. We can leave BeginTextBlock(), EndTextBlock() and RenderText() as empty functions. That just leaves RenderImage, which receives an ImageRenderInfo; this has very few functions, one of which is GetImage() which returns a PdfImageObject instance. In turn, PdfImageObject incudes a GetDrawingImage() function that returns a good old standard System.Drawing.Image. That’s it ! We can dump it to a file, save in a list for later, whatever.
That’s basically it. It is however a bit of a cheat; we aren’t saving the exact original image as it is stored in the PDF file, we are re-compressing it. For example, using a test pdf with but a single jpg in it, the pdf file happened to be 233KB. The resulting extracted jpg was 330KB. Not that I care for my original purpose.
But you aren’t a real programmer unless you have a little delve around the edges. Lets take a closer look at ImageRenderInfo. There is a function GetImageAsBytes(), this sounds more interesting. So, lets see:
var imageObject = renderInfo.GetImage(); var data = imageObject.GetImageAsBytes(); Debug.WriteLine(String.Format("0x{0:X2} 0x{1:X2} 0x{2:X2}, 0x{3:X2}", data[0], data[1], data[2], data[3]));
The debug output shows the first three bytes are 0xFF 0xD8 0xFF, 0xE0 which just so happens to be the opening bytes of a JPEG ! So, lets dump that array to a file:
File.WriteAllBytes(@"C:\temp\hacktest.jpg", data);
Et voila, a 230K JPG file ! Allowing a few KB for PDF overhead, this shows that it is the original JPG, not compressed. Sweet !
There are, however, more than one image format that a PDF can store. It can, for example, store a PNG .Again, looking imageObject, we see GetFileType() that returns a string. If you go to the definition of this function then we see this:-

Yay ! We see this returns the file extension, though it turns out this is without the preceeding dot character that we’d see with standard Path functions. So, now we have:
var imageObject = renderInfo.GetImage(); var data = imageObject.GetImageAsBytes(); var fileName = @"C:\Temp\hackfile." + imageObject.GetFileType(); WriteAllBytes(fileName, data);
To confirm this works as expected, I created a PDF hopefully containing one JPG and one PNG – I say “hopefully” as I’m never quite sure what the PDF creation software might do with images; I put the two images in a Libre Office document and exported to PDF, ticking the Loseless compression button:

I uploaded the pdf to http://www.extractpdf.com/ just to check the contents, and sure enough there’s one JPG and one PNG stored in there. Then fired that at the image extraction code and voila, I got back exactly the same images that I’d originally imported into the document. Jolly good !
Well, what else could we do ? Well, in practice a PDF may be full of images, big ones we want plus, for example, teenie little icons and such like that we are not interested in. So could we perhaps only export images above a certain size ? Lets see what imageObject might have; there is a function “Get()” which takes as it’s parameter PdfName enum (or whatever it is):-

Well lookie here, there is WIDTH (also HEIGHT and an absolute shed load of other items). The function returns a string so we can get the width as:
var widthInPxels = Convert.ToInt32(imageObject.Get(PdfName.WIDTH));
Clearly, the massive list of PdfName definitions can’t all apply to an image and indeed most just result in Get() returning null, which is fair enough. But further peeking at imageObject shows a GetDictionary(). Lets see what the VisualStudio’s immediate window can come up with:
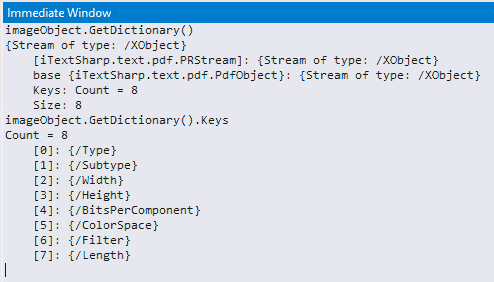
There is a PdfName equivalent to each of the eight dictionary items so I’m guessing that is what we can access via the Get() function. Isn’t this fun ?
Other things we might like to consider is what if the PDF file is encrypted (i.e. password protected) ? Well, I don’t know how to deal with that (hint: go to definition of PdfReader, there are loads of constructors there including some where you pass in “byte [] ownerPassword”) but at least we can detect the situation. Going right back to the PdfReader() instance, there is a function IsEncrypted().
Well, playtime is over. I’ve wrapped this all up into a nice little helper class which I use.
using System; using System.IO; using iTextSharp.text.pdf; using iTextSharp.text.pdf.parser; namespace PdfImage.Helpers { /// <summary> /// Helper lass to dump all images from a PDF into separate files /// </summary> internal class ImageExtractor : IRenderListener { int _currentPage = 1; int _imageCount = 0; readonly string _outputFilePrefix; readonly string _outputFolder; readonly bool _overwriteExistingFiles; private ImageExtractor(string outputFilePrefix, string outputFolder, bool overwriteExistingFiles) { _outputFilePrefix = outputFilePrefix; _outputFolder = outputFolder; _overwriteExistingFiles = overwriteExistingFiles; } /// <summary> /// Extract all images from a PDF file /// </summary> /// <param name="pdfPath">Full path and file name of PDF file</param> /// <param name="outputFilePrefix">Basic name of exported files. If null then uses same name as PDF file.</param> /// <param name="outputFolder">Where to save images. If null or empty then uses same folder as PDF file.</param> /// <param name="overwriteExistingFiles">True to overwrite existing image files, false to skip past them</param> /// <returns>Count of number of images extracted.</returns> public static int ExtractImagesFromFile(string pdfPath, string outputFilePrefix, string outputFolder, bool overwriteExistingFiles) { // Handle setting of any default values outputFilePrefix = outputFilePrefix ?? Path.GetFileNameWithoutExtension(pdfPath); outputFolder = String.IsNullOrEmpty(outputFolder) ? Path.GetDirectoryName(pdfPath) : outputFolder; var instance = new ImageExtractor(outputFilePrefix, outputFolder, overwriteExistingFiles); using (var pdfReader = new PdfReader(pdfPath)) { if (pdfReader.IsEncrypted()) throw new ApplicationException( pdfPath + " is encrypted."); var pdfParser = new PdfReaderContentParser(pdfReader); while (instance._currentPage <= pdfReader.NumberOfPages) { pdfParser.ProcessContent(instance._currentPage, instance); instance._currentPage++; } } return instance._imageCount; } #region Implementation of IRenderListener public void BeginTextBlock() { } public void EndTextBlock() { } public void RenderText(TextRenderInfo renderInfo) { } public void RenderImage(ImageRenderInfo renderInfo) { var imageObject = renderInfo.GetImage(); var imageFileName = String.Format("{0}_{1}_{2}.{3}", _outputFilePrefix, _currentPage, _imageCount, imageObject.GetFileType()); var imagePath = Path.Combine(_outputFolder, imageFileName); if (_overwriteExistingFiles || !File.Exists(imagePath)) { var imageRawBytes = imageObject.GetImageAsBytes(); File.WriteAllBytes(imagePath, imageRawBytes); } // Subtle: Always increment even if file is not written. This ensures consistency should only some // of a PDF file's images actually exist. _imageCount++; } #endregion // Implementation of IRenderListener } }
Bear in mind my original reason for extracting images – it means I could leave out error checking that a real app oughta do (for example what if output directory were read-only?). It is used in conjunction with a helper class:
namespace PdfImage.Helpers { public static class PdfHelper { public static int ExtractImagesFromFile(string pdfFileName, string outputFilePrefix, string outputDirectory, bool overwriteExistingImages) { return ImageExtractor.ExtractImagesFromFile(pdfFileName, outputFilePrefix, outputDirectory, overwriteExistingImages); } } }
Bit over the top ? Well, I put this stuff in a class library; if I exported the original ImageExtractor class then I’d also be exposing the iTextSharp’s IRenderListener interface and I don’t like that. Plus I dare say the little helper class will see a few additional functions one day (such as PdfIsEncrypted(string pdfFileName).
Very useful post, thanks
This is very helpfull.